Racing into Machine Learning: Data Readiness and the Developing World
Machine Learning (ML) technology can help us draw important insights from data, but it is imperative to recognize a model is not an end in and of itself. Based on BFA’s experiences engaging with early-stage partners in emerging markets, such as Catalyst Fund investees, we have seen the consequences of rushing into machine learning without a clear understanding of the underlying data. As a business, misreading this data can cause you to chase errant hypotheses around the needs of your core set of customers, which in extreme cases, can cost you everything. To this point, we recommend here that fintech startups and other financial institutions focus first on producing and refining this data as the fuel to get an insights engine running, before exploring increasingly sophisticated models.

Navigating the AI/ML Landscape
Artificial intelligence (AI) and machine learning are some of the hottest buzzwords of today. With the increased exposure, there is an associated growth in the number of businesses and individuals eager to incorporate these exciting tools into the fabric of their operations.
In this air of excitement and hype, innovators and entrepreneurs seeking to develop an AI/ML strategy may raise a whole host questions:
- “Should I use one of these cool neural networks I keep hearing about?”
- “Is simple regression too basic for the problem at hand?”
- “Is there something in between I should be looking at?”
The answers lie in your data.
“It is a capital mistake to theorize before one has data. Insensibly, one begins to twist the facts to suit theories, instead of theories to suit facts.”
— Sherlock Holmes
While AI/ML is truly remarkable, to begin to navigate the exponentially growing number of options available requires a level of prudence, experience, and familiarity with your underlying data.
Data as Fuel
“Information is the oil of the 21st century, and analytics is the combustion engine.”
— Peter Sondergaard, SVP, Research at Gartner Inc.
For the machine learning engine, data is the fuel. Just as a race car driver would never fill up with fuel meant for a lawnmower, we should not be training complex models “filled” with low-quality data. We should first look deeply at the volume, tidiness & veracity of the data we have, and only then choose a suitable model that allows us to quantitatively draw insights.

In most cases, training neural networks and other sophisticated models from scratch is like driving an F1 race car to get across your living room.
This is to say that cutting-edge machine learning models can be absolutely wonderful for specific situations in the right setting: you’re in a large enough space with the need for high performance and you have a substantial amount of high-quality fuel (data). But treating this approach as the go-to solution for every problem is often overkill, potentially destructive and ultimately may not even get you where you want to go. In fact, it is imperative to first have the right fuel to even make it past the starting line.
A Framework for Choosing the Right ML Model
Data Readiness: A Spectrum
In BFA’s work with data-driven entities in the developing world, we have identified what we see as a clear opportunity for businesses to reduce costs, in which modern computing technology, statistical methods and ML models play a strong role. We hypothesize that this reduction of cost translates to higher net revenue for the entity. Better-margin business models, higher employment rates and manageable fees on financial services for low-income populations, for instance, can become attainable goals rather than lofty ideals.
We also have seen a spectrum of the quality and quantity of the data fueling these entities’ predictive models, which can at times feel more like minivans or construction cranes than race cars. The current state of each of these organizations — whether a fintech startup, an SME, a financial institution or a financial authority — is distributed along a path to full “data readiness.”
At the entrance to the path lie the strategies for generation and collection of quantitative data: surveying, focus groups, and instrumentation of products. At the other end is the ideal goal of fully-automated machine learning incorporated into operations and directly fed into the decision-making process.
The Insights Engine
The process of data generation and predictive machine learning modeling (“model-building”) must be architected such that it’s iteratively driven by new insights (“learnings”). As a data-driven organization, you would make your way up the “stack,” building on context and experience to produce data-driven hypotheses that inform quantitative features and ML models.
Equally important: You need to make sure to capture the insights produced by the model, feeding these learnings back into a new, deeper understanding of the context to inform the next iteration. Optimization requires not only a foundational understanding of the real-world context but also a feedback mechanism to inform the next iteration.
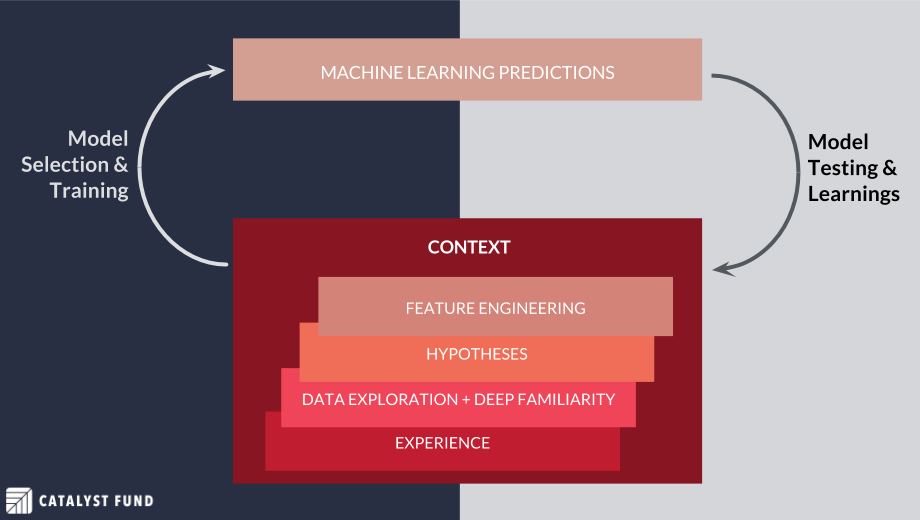
Within this framework, we have begun to develop a sense of which approaches to machine learning might work best for an entity based on its position along the data-readiness spectrum. In the example below, we built on our contextual knowledge of smallholder farming, on WorldCover’s experience and on data generated via surveys during their field research. Only after acquainting ourselves with each of these elements did we begin to explore using this data to build testable hypotheses, extract relevant features and feed them into the ML layer.
Case Study: Applying Predictive Analytics to Sales Lead Conversion
In a recent Catalyst Fund engagement, we partnered with WorldCover to further develop customer relationships and trust around their research on affordable microinsurance drought policies for smallholder farmers’ crops in northern Ghana.
As a follow-up to this engagement, we focused on a quantitative analysis to help WorldCover determine which communities would be best to prioritize for a sales visit, based on historical data from similar communities they had previously visited. In other words, we wanted to predict the most influential factors for a potential customer to move through WorldCover’s lead funnel.
With our investigative hats on, we began by examining their data, the heuristics and hypotheses they had already defined and explored, and the key metrics they hoped to hit.

Predictive Analytics for the Lead Funnel
Roughly speaking, the lead funnel for smallholder farmer customers consists of:
- Step 1: Visiting a community to get to know the farmers, and proving them with details of a given insurance policy
- Step 2: Collecting information from interested farmers
- Step 3: Returning to the community to sell policies to interested farmers
- Step 4: Collecting payments for policies that are purchased
Our goal was to use any community data available before a visit to prioritize travel, based on the predicted percentage of payment conversions by the community. In other words, given the results of Step 1, how might we predict the results of Step 4? On a high level, these predictors available after Step 1 included: demographic data, weather data, survey data and results from past visits.
As a first pass, we explored linear and logistic regression models, which are two of the simplest predictive ML models around (relative to random forests or neural networks, for instance). The relatively quick implementation and intuitively interpretable results of linear and logistic regression models mean they are often the shortest path to usable insights. These models surfaced which factors have the most predictive power and which ones can be discarded. In this case, the trained model was able to prioritize the communities such that they could be split roughly into “good to visit” vs. “less good to visit.” This initial model, while not necessarily cutting-edge from a technical perspective, was enough to reveal insights into how we could improve the data collection process.
For instance, the model illuminated the fact that the initial data was gathered only from interested farmers after Step 2. However, the data would have been even more useful if it had been collected from all farmers in the community during Step 1. If we had focused first on training a sophisticated model with a longer implementation or less intuitive output, we might have missed out on this somewhat fundamental insight about the real-life data generation process.
“We shape our buildings, thereafter they shape us.”
— Winston Churchill
Armed with this knowledge, the next cycle of visits to farmers will now generate more relevant and timely data. The symbiotic processes of data generation, hypothesis building, ML modeling and extraction of learnings can continue to feed one another in iterative cycles toward an optimal system and more sophisticated modeling techniques as needed.
The Right Foundation for Data-Driven Insights
The important takeaway here is that producing ML models is not only about gaining a “high-tech” badge, or about “keeping up with the Joneses.” Rather, these technologies are a means to a greater end, which is to achieve your business’ goals more efficiently and effectively.
“The goal is to turn data into information, and information into insight.” — Carly Fiorina, former CEO, Hewlett-Packard Co.
By choosing models that fit your data rather than your personal expectations, you can focus on drawing valuable insights about the collection, organization, and optimization of your data. Only by building this solid foundation can you provide your insights engine with the right fuel, and accelerate into the wide world of powerful and sophisticated ML techniques.
Originally published at letstalkpayments.com on August 1, 2017.


