Next-Level Computer Vision: When Off-the-Shelf Software Options Don’t Cut It
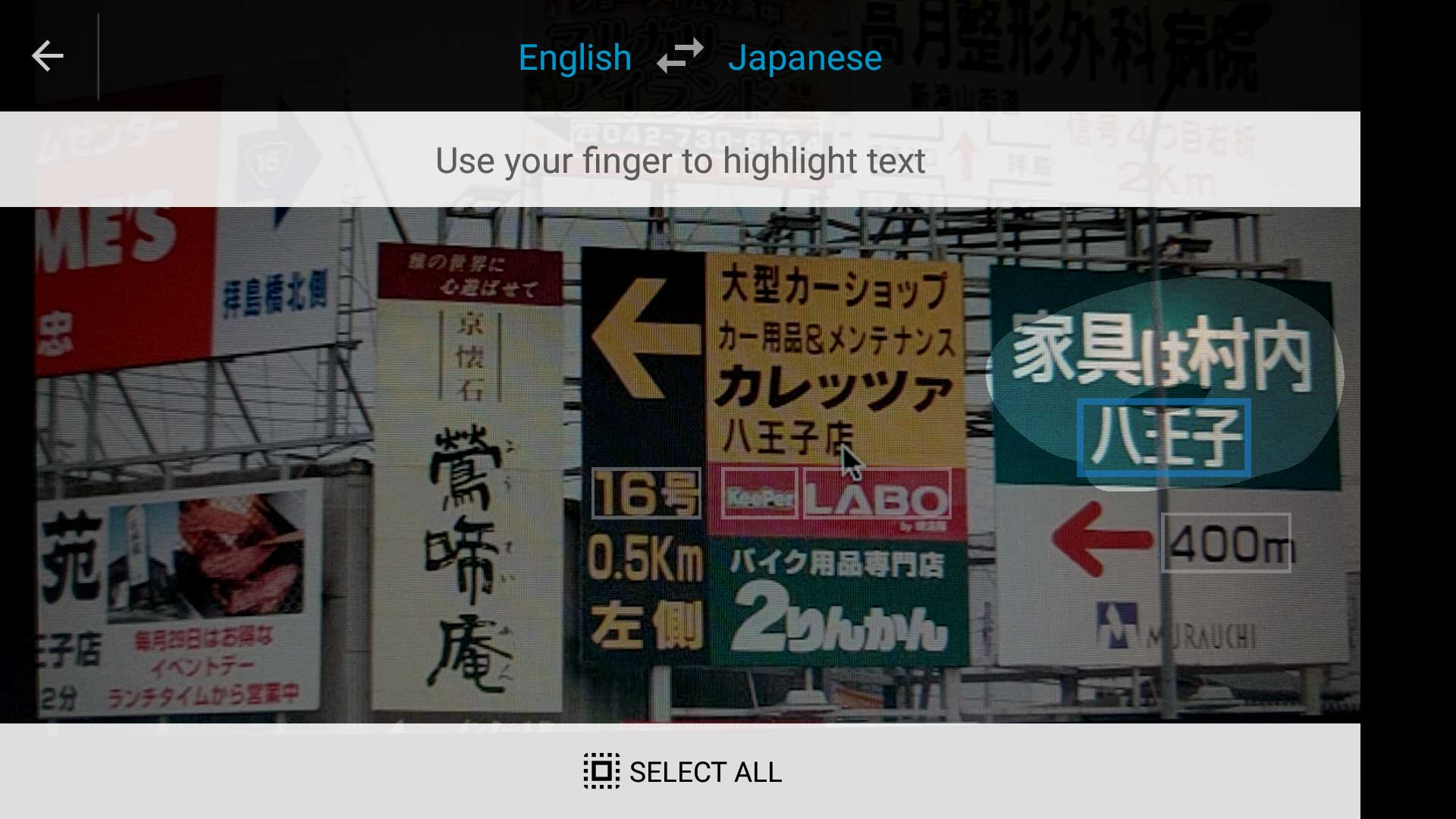
Let’s say you’re in Tokyo and you see a billboard with a catchy photo. You want to know what the billboard says, but you can’t read Japanese. No problem! You can use Google Translate to take a picture of the billboard, highlight the text you care about, and then your phone will translate it into English. This is a prime example of computer vision, which allows us to automatically extract, analyze, and understand information from images due to recent advances in machine learning.
Generic software solutions don’t always cut it for OCR
Given these advances, we thought it would be straightforward to adapt off-the-shelf computer vision programs to pull important data from identification documents, a task that most fintech companies face in the field. Ultimately we found that off-the-shelf computer vision programs were not sufficiently accurate, but that open-source computer vision libraries could be adapted to create effective custom solutions for Optical Character Recognition (OCR).
We worked with Smile Identity, a fintech startup with operations in Sub-Saharan Africa and the Catalyst Fund’s first digital identity investee, to pioneer a solution to match selfies with the pictures on official documents and to extract important bio details (like name, DOB, etc.).
To meet Smile ID’s needs, the solution needed to:
- Match selfies with the pictures on official documents
- Extract important bio details (like name, DOB, etc.) into “field value”pairs (i.e., Name: John Smith, ID no: 123456).
We found that the most popular off-the-shelf solutions, Google Cloud Vision and Microsoft Azure Computer Vision, could solve the facial recognition part of the task (i.e. verifying the selfie photos), but were only partially accurate in recognizing and extracting the bio details text.
The off-the-shelf solutions faced two key challenges in delivering results on the text recognition task consistently. First, the exact nature of official IDs made off-the-shelf solutions unsuitable for the task; identification documents typically feature intricate security features in the background to reduce identity fraud. Second, the quality of the images that customers would take with their phone cameras was often sub-par, limiting the accuracy of text recognition. As such, Google Cloud Vision was only accurate about half of the time, while Microsoft Azure Computer Vision had an even lower success rate. Even when the text recognition task was completed successfully, we then had to format the outputs further to extract the ‘field label: field value’ pairs.
Building a custom solution
Given the limitations of the off-the-shelf solutions, we explored building a custom solution to encompass both the facial recognition and text extraction tasks using existing open-source computer vision libraries, i.e., Tesseract and OpenCV. Tesseract is the most popular open-source OCR engine (sponsored by Google) that allows for robust analysis of images without background noise and OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library. Due to its versatility and the completeness of its library, we chose to move forward with OpenCV to build the computer vision solution.
By applying deep learning and using template matching (finding small parts of an image which match a template image), we created a custom image analysis pipeline for both facial and text recognition. Our custom solution easily processed images of identification documents, extracted the information we needed, and populated the data into a repository for downstream application processing.
Building a custom, bespoke image processing solution increases accuracy and flexibility, but requires a higher initial investment in development time and costs. Specialized firms like Smile Identity are taking on this development effort in underserved geographies like Sub-Saharan Africa, where the diversity of ID types, standards and languages present a real problem for fintech companies trying to rapidly onboard new users, and collect and verify KYC documents. By using custom image pre-processing and an Android SDK that improves user experience and image capture quality, Smile Identity is able to achieve better results for its customers than generic off-the-shelf solutions.


