Promising AI Applications to Help Shopkeepers Manage Business
Four Lessons for Training Computer Vision Models
Artificial Intelligence (AI) technologies offer many opportunities to augment and extend business abilities, but applications are still nascent and integrating them can be difficult and laborious. For example, computer vision applications may one day be used to assess photographs to help financial service providers evaluate inventory and creditworthiness of micro, small and medium enterprises (MSMEs). BFA has been at the forefront of testing AI and computer vision applications for mom-and-pop shops through the FIBR program, with the support of Mastercard Foundation.
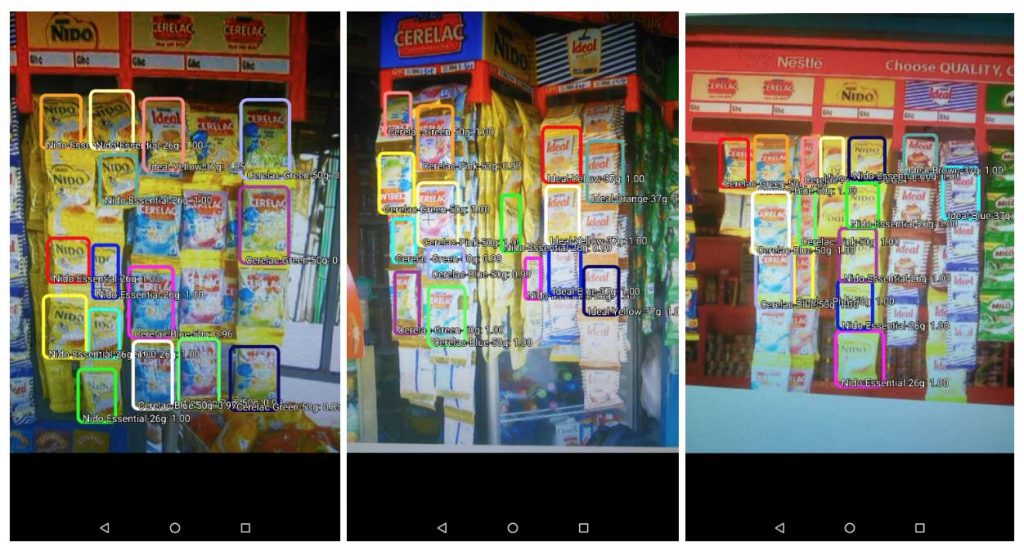
Most recently, we tested a computer vision application in partnership with Optimetriks, a startup that helps fast-moving consumer goods (FMCG) companies to get real-time visibility on what happens in informal outlets in Africa. Here, we outline our initial takeaways on how to use computer vision models to support small shops, and how to get started training models to evaluate images.
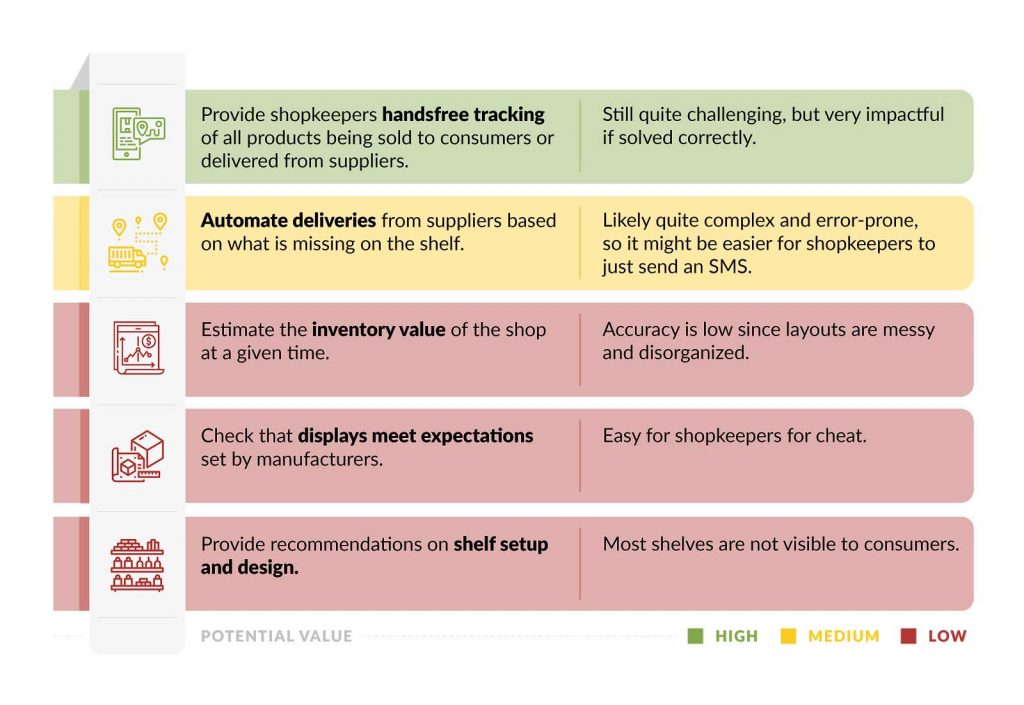
While many use cases are still ways down the road, there are still promising use cases for the technology:
Whatever the use case, the power of a computer vision application is based on its ability to accurately recognize what is contained in an image. As such, training the computer vision model is critical to achieving acceptable levels of accuracy. Training is a multi-step process that can be prone to errors and is important to approach these errors with patience and rigor. Approaching this journey carefully, from the initial setup and data transformation to the training and evaluation, will mean the difference between a model that has sufficient recognition accuracy to add value and one that does not.
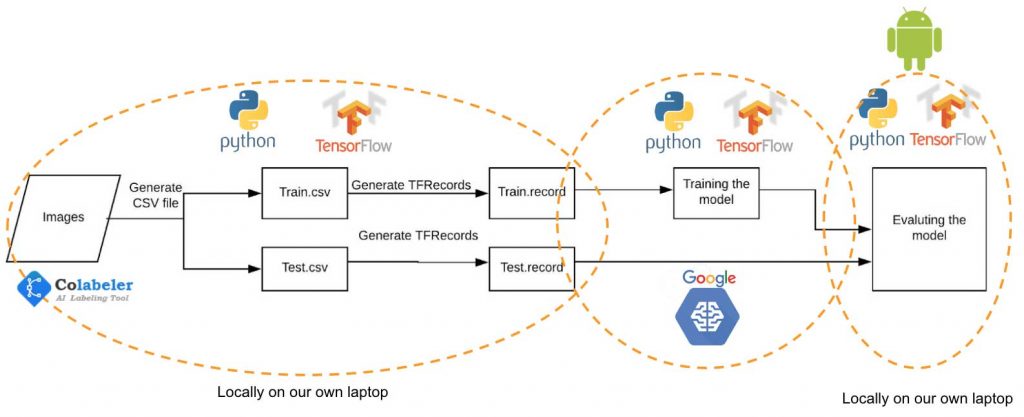
Given the complexities of training, it is valuable to keep the following takeaways in mind:
1. Selecting libraries and tools that have strong communities and ample documentation is critical to troubleshooting
Initially, we had chosen the new free open-source library for deep learning released by fast.ai because it uses some of the most cutting-edge techniques to deliver higher accuracy models with less training time. However, because of how new this library was, we found that it lacked the documentation needed to achieve the results we wanted in the time allotted. Instead, we pivoted to TensorFlow, another open-source software library developed by the Google Brain team, due to the strong community and copious resources they make available to assist with training as well as ease of integration with mobile.
We are not endorsing one platform over another because this space is still rapidly evolving. In fact, some of this information is probably already stale! In considering what platform to choose, consider how active its community is and the extent of the documentation available.
2. A hundred labels per product can produce a model with 80 to 90 percent recognition accuracy
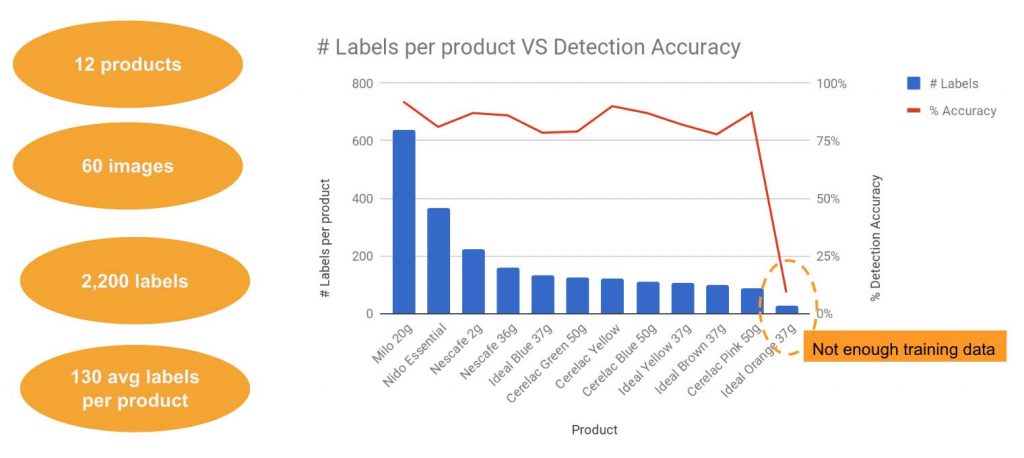
Before images can be used to train a computer vision model, they must first be annotated (labeled) with metadata to indicate each product and where in the image it is located. Tools such as Colabeler, RectLabel, or LabelBox can assist with this process. To ensure adequate accuracy, meaning how many times the algorithm can successfully detect a particular product presented in a photo, each product should be labeled at least 100 times.
We used Colabeler because it is free, easy to use, has multi-platform support for both Mac and Windows, and has multiple export formats, allowing us to use the annotations with different machine learning libraries. Over two working days, we labeled 12 products across 60 images resulting in a total of 2,200 labels. On average, each product was labeled 130 times. We found that additional labels did not improve accuracy. The model achieved 80 to 90 percent recognition accuracy for products, whether they had 600 labels or 100. For one product, we only collected 20 labels, and this decreased recognition accuracy to less than 10 percent. While the achieved accuracy is not state of the art for computer vision in general, it is significant in a sector marked by a lack of usable data. By providing new, confidently-stated data that was not accessible before, the application moves the sector forward.
3. Ensure products are not blocked or obscured in the images
It is difficult to get accurate information when items in the images are obscured due to poor definition, or because they are stacked on top of each other, located deeper on a shelf, or placed in a container.

For example, early in the training process, our model was getting confused between bushes and the greenish color of one of the labeled product sachet. This can be addressed using negative samples (e.g., a “non-product” category) in the training set, for commonly misidentified objects.

4. For an additional cost, cloud computing can save time and effort
The training process can either be run on a local machine or can be dispatched to the Google Cloud, for example. Training locally is the cheapest and simplest to configure, but can also be the slowest depending on the speed of your machine.
To train more quickly, we used the Google Cloud Platform. Based on our observations, Google Cloud was four times faster, which reduced training time from 20 to five hours (conducted five times). The drawback to using Google Cloud is the complexity of additional steps to configure and the cost of renting the cloud-based training machines. While training a typical model cost us about US $30, some configurations trained on the Google Cloud Platform can cost up to US $130. Google Cloud provides a pricing calculator that can be used to estimate the cost for specific configurations.
Once you have trained the model you can embed it in a mobile app and test it with your smartphone’s camera. Training the model with TensorFlow makes object detection extremely portable and available offline in smartphone devices. It also makes detecting of object data easier by allowing instant feedback through the video feed.
AI for Good and for More People
Tempered by the backdrop of hype, AI and computer vision can appropriately unlock new opportunities to develop solutions for low-income populations, even though there are still barriers to widespread availability and use of smartphones. Smartphones are increasingly affordable and low-to-medium range models can pack enough of the computational punch required to process computer vision algorithms to unlock Practical AI Superpowers (read the report) more broadly. Computer vision is a promising way for operators in last-mile markets to gather real-time data and business tools and financial services that could help low-income customers survive and grow.


