The DataStack blueprint
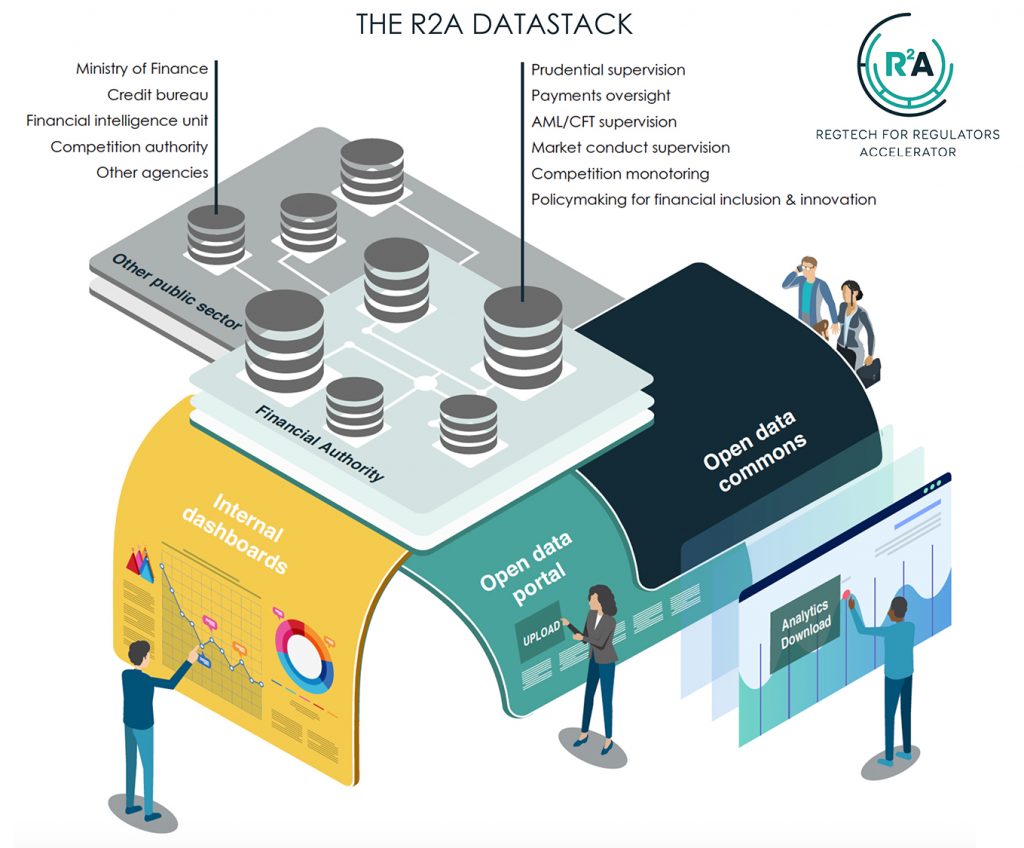
The DataStack, introduced below and elaborated on in our more detailed report, is both (a) a map detailing necessary factors in creating equitable real-world solutions for the increasing data divide in the digital realm, and (b) a blueprint for combining technical tools into a layered architecture to enable such solutions. We present a particularly strong case for this approach in the supervision of financial sectors and in the innovation of digital financial services and are also actively exploring further avenues for impact beyond finance, including climate action, pandemic response, and more.
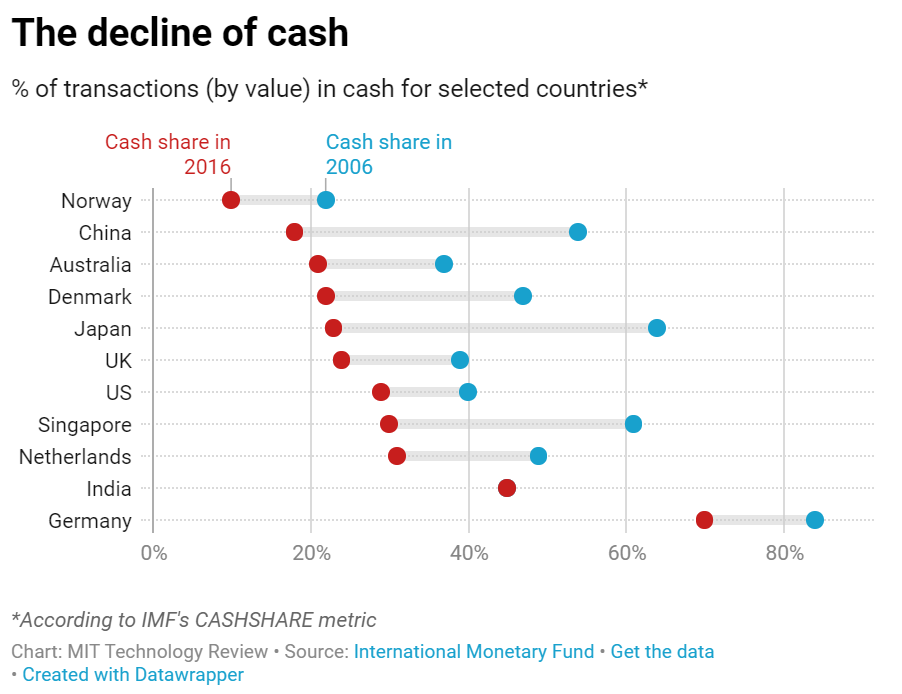
The digital transformation of the economy and the financial sector has been evident for three decades. Cards first, and then online means of payment have increasingly substituted cash. The offer of digital credit is increasing steadily. From Norway to India, cash use is declining and digital currencies and channels are increasingly used. The coronavirus pandemic is critically accelerating this trend. Better connectivity, cheaper mobile technology, new products, and improved customer experience make this shift global. In the past few years, the boom of non-cash means of payment has been driven by developing markets, with Russia (compound annual growth of 36.5%), India (33.2%), and China (25.8%) as notable movers during 2015-16. Mature markets maintained steady growth of more than 7%. For millions of people, this digitization is transformative – think of Kenya where financial inclusion jumped from 6.5% to 73% over 10 years, mostly driven by digital money.
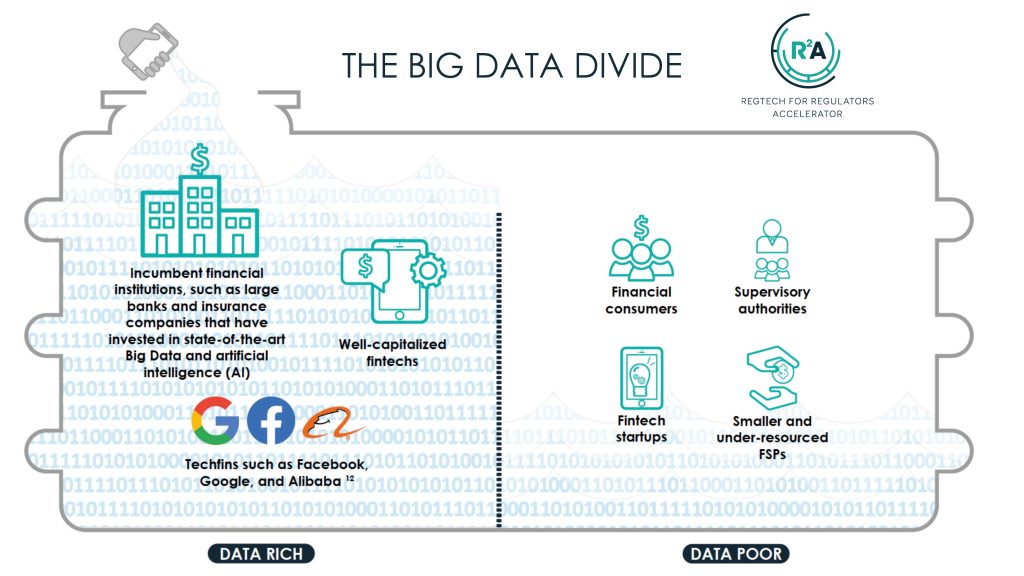
The Bank for International Settlements (BIS) noted that COVID-19 is accelerating the adoption of digital payments, and countries are expanding digital payment infrastructure with more online, mobile, and contactless. Forecasts published before the pandemic predicted that non-cash transactions will post a CAGR of 12.7% through to 2021, with developing markets set to show a 21.6% CAGR, led by emerging Asia at 28.8% over the next five years. By 2021, developing markets are expected to account for around half of all non-cash transactions worldwide, overtaking the mature markets for the first time, whose current share stands at 66.3%. The figures around the digitization trend will only increase as an outcome of social distancing measures. The coronavirus pandemic has thrown into relief the deepening “Big Data divide” between financial service providers who have successfully harnessed digital technology, artificial intelligence (AI), and Big Data (the “data haves”), and a growing group of public and private sector stakeholders who lag behind in the digitization and dataficiation revolution (the data “have-nots”).
This imbalance of power has the potential to skew the development of digital financial ecosystems in favor of a few large players (i.e., Google, Amazon, PayPal, and the like) that could cannibalize financial sectors – in 2016, e-wallets accounted for 8.6% of non-cash transactions (a volume of 41.8 billion), of which 71% were already facilitated by BigTech providers. This “data divide” threatens to favor a few players, reduce competition, and undermine innovation. The pandemic is accelerating a shift in the balance of data processing power in favor of the “data haves,” enabling them to extract powerful insights about the behaviors, preferences, and whereabouts of their customers. The crisis is reinforcing scale and network effects that confer disproportionate advantages, not only relative to their competitors, but also vis-a-vis the populations that they serve and the financial authorities that oversee them.
There are two significant challenges that emerge from this picture.
First, even before COVID-19, financial authorities were ill-equipped to oversee the digital economy and digital financial services, given the proliferation of new data sources, new financial products, and a more diverse pool of consumers and providers (especially fintech firms). The market has been speeding ahead with digital innovations and consumers are growing ever hungrier for streamlined, ubiquitous, and immediate financial services. Financial authorities, for their part, currently lack the resources and data science chops to handle the prodigious amounts of data being harvested by fintech firms and BigTechs, and they have been slow in adopting Big Data and AI owing to a combination of resource constraints, legacy culture and infrastructure, and legitimate concerns surrounding cybersecurity and operational risk. In the context of ever broader and faster diffusion by digital financial services, this divergence in technological readiness poses a material risk to the health of the financial sector by creating supervisory blindspots and slowing reaction times. To establish knowledge and evidence that drive targeted, risk-based decision-making to promote financial inclusion, maintain stability, pursue consumer protection, strengthen integrity, sustain competition, and drive innovation, financial authorities need to (urgently) access new datasets and deploy smart analytical tools. Latest generation supervisory technology (SupTech) promises to close the gap with the market as well as vastly improve supervisors’ capabilities in other domains (see our paper co-authored with the Bank for International Settlement). This entails harvesting higher volumes and varieties of data than were available or digestible before (both structured and unstructured such as web data). It necessitates a robust yet nimble data infrastructure, including advanced analytics that enables targeted, timely, risk-based oversight, and market interventions. Since 2016 we have been working to address the Big Data divide through the RegTech for Regulators Accelerator (R2A). R2A partners with standard-setting bodies, financial authorities, and technology firms to pioneer SupTech applications to deepen the oversight of the marketplace and enhance policy intelligence. R2A has been successful in developing new applications that are being rolled out across the world in areas such as prudential, anti-money laundering, and market conduct supervision.
Second, from the United States to Nigeria, in order to level the playing field between the data-haves and the have-nots, the latter need to be equipped with technology and data of equal caliber. But such power doesn’t come cheap. Indeed, accessibility and affordability of data, not to mention the tools to convert data into meaningful and actionable insights, have provided much of the impetus behind the open data and financial inclusion movements.
Existing solutions to enhance supervision and open data to support innovation are inadequate. Off-the-shelf supervisory applications carry hefty price tags and lock organizations into rigid, siloed architectures that don’t allow for timely response and to integrate intelligence between different departments. Open Data Portals (ODP) often underdeliver on their promised potential since data are frequently sparse and scattered across multiple platforms without uniform metadata standards or consistent user interfaces (UI) and user experiences (UX). Much are kept closed, either purposely or due to lack of technical capacity, and poorly presented to the public. Furthermore, the most commercially valuable data, such as granular, high-frequency market data (e.g., house prices and sales), are rarely available from Open Data Portals and can only be sourced from third-party providers, often at a considerable cost. Even when granular data are available, convoluted data structures and unwieldy formats make it cumbersome to check their validity. The plethora of firms specializing in the consolidation and standardization of free public data for a fee testifies to this data management pain point.
In the report that we published today – finalized before the COVID-19 outbreak – we shed light on this growing “Big Data divide,” which in some sense has been eclipsed by the longer-running debates regarding the “digital divide” (referring more to hardware than data per se). We show how the imbalance in processing power has the potential to skew the development of digital financial ecosystems in favor of a few large players, which can undermine competition, innovation, and inclusion unless adequately regulated. To bridge this divide, we propose a new Open Data Commons (ODC) that guarantees access to rich and plentiful data, as well as the tools to make them meaningful and actionable. This vision rests on a technology solution we call the DataStack: a new data architecture for regulators and supervisors incorporating the latest generation of Big Data and AI tools. It is designed to address gaps in supervisory capacity and capability opened up by Big Data and the digital transformation of the financial sector.
In the report, we take financial authorities on a journey from the enhancement of their capabilities through SupTech to the development of an expanded variety of ODC, which we refer to as DataStack. The DataStack is a modular, streamlined, end-to-end data architecture that leverages an interoperable data platform and advanced analytics tools to generate meaningful, actionable insights in digestible formats for multiple personas. In our vision, the DataStack can rebalance the Big Data divide and create a more equitable playing for all stakeholders in the digital financial sector in terms of access and affordability (see figure below).
An Open Data Commons for the post-pandemic world
The COVID-19 crisis has accentuated this disparity in Big Data capabilities. As with e-commerce and teleworking, digital financial service providers, from branchless banks to mobile money operators, have stepped in and scaled up in short order to address the severe dislocations in traditional financial distribution wrought by lockdowns and layoffs. In the UK, for instance, Fintech firms are playing a crucial role in helping to disburse relief funds to struggling small enterprises who have limited access to traditional credit. BigTechs such as Apple and Google are leading the way in designing and deploying contact tracing tools. Speed, scalability, and streamlined (contactless) customer interface have proven critical in this crisis.
In the post-COVID era, digital will become even more dominant, and cashless will be king once the pandemic passes. A possible corollary is that the Big Data Divide sketched out above becomes even more skewed in favor of fintech providers. This point has been underscored by the relatively slow and scattered response of governments to the COVID-19 crisis. Their technology infrastructures that are responsible for delivering economic relief have been exposed as woefully inadequate and antiquated. A widely circulated example of this was the call for COBOL programmers by one state labor bureau in the US, whose decades-old claims handling system was struggling to handle the tsunami of unemployment claims. The UK government’s contact tracing app has been riddled with problems. The haphazard and tardy disbursement of vital financial aid is to some extent symptomatic of gaps in data and analytics as well. Identifying pandemic exposures and deploying relief in a targeted and virtually real-time manner – already a core objective of risk-based supervision in the era of digital financial services – will become even more urgent than before.
In order to address these shortcomings, financial authorities need to restock their data warehouse, reengineer their data architectures, and retool their analytics – and fast. Given budgetary constraints, on top of existing legacy technology and legal constraints (i.e., so as to be interoperable with existing systems), the solution also needs to be cost-effective and nimble. The DataStack blueprint that we outline in the paper meets those requirements by optimizing for cost and openness in terms of interoperability and data sharing, and by relying heavily on open-source software with industry-standard security features.
In order to address these shortcomings, financial authorities need to restock their data warehouse, reengineer their data architectures, and retool their analytics – and fast.
For consumers, the COVID-19 crisis amplifies concerns around privacy and confidentiality. Companies will harvest ever greater amounts of personal and private information in pursuit of real-time contact tracing. Although the grim reality of the pandemic makes this delegation of responsibility unavoidable (even desirable given their superior technology chops compared to governments’ in-house capabilities), it must be matched by a commensurate increase in transparency and openness to competition.
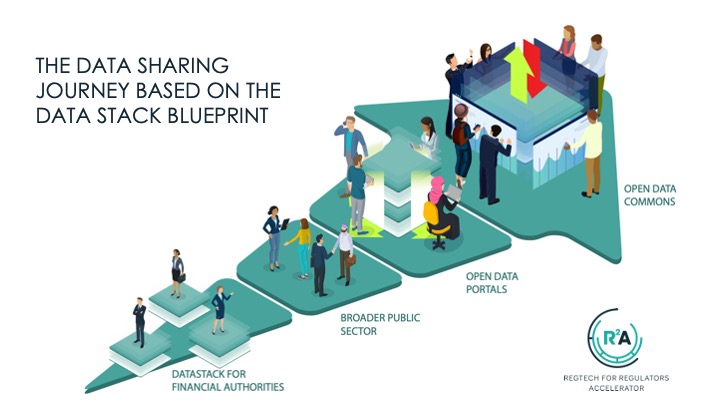
Enter the Open Data Commons
Building on the DataStack platform developed for financial authorities, the ODC makes select data and analytical tools openly available to the public. For instance, were authorities to use financial transaction records to monitor population movements in real-time, the public might benefit from having access to such information in order to avoid clusters of people at a given time (say a busy farmers market where many people are making non-cash purchases at a particular point in time, which raises an alert). Call it data-driven social distancing. Alternatively, small technology providers might use the data harvested from mobile phones by the BigTechs to develop alternative or ancillary tracking solutions and/or provide more effective pandemic relief, thereby helping to address overconcentration by BigTechs in this space. Regardless of how the data is deployed, greater transparency and visibility is the point. The ODC we sketch out in the report provides the blueprint for such a world. It cannot come soon enough.


